Why High-Quality Speech Data Requires Careful Investment
Building high-quality speech datasets is expensive and time intensive. This article explains why careful prioritization, sustainable economics, and collaboration across community and commercial models are essential for broader language coverage.
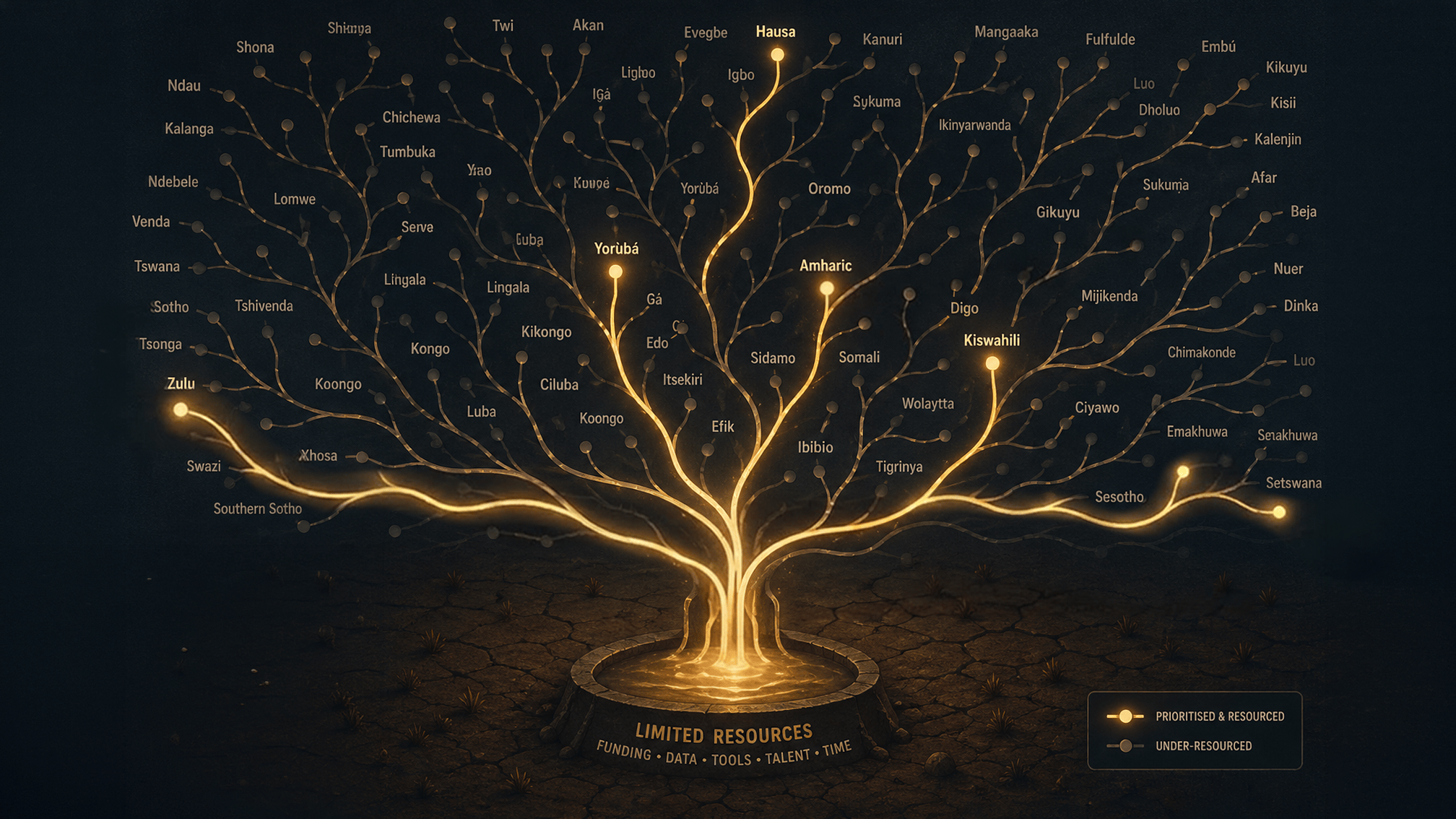
As demand for multilingual speech AI grows, so does the need for high-quality speech datasets across more languages and dialects.
A common question in the industry is:
Why can’t every speech dataset be built at once?
The answer is simple: building high-quality speech data is expensive, complex, and time intensive. Expanding language coverage requires careful prioritisation, not only to maintain quality, but to ensure investment reaches underserved languages rather than being repeatedly concentrated in the same areas.
Producing speech data at quality takes substantial human effort.
A recent field study, Cost Analysis of Human-corrected Transcription for Predominately Oral Languages, found that transcribing just one hour of Bambara speech required 30-36 human labour hours, before broader QA, packaging, and delivery processes were factored in.
Building Speech Datasets Is More Than Recording Audio
Producing production-ready speech datasets involves far more than asking contributors to read prompts into a microphone.
A professional speech data pipeline typically includes:
- Recruiting diverse native speakers
- Managing informed consent and contributor onboarding
- Recording and validating usable audio
- Transcription and annotation workflows
- Multi-stage linguistic quality assurance
- Dataset formatting, packaging, and documentation
Each of these steps requires specialised processes, trained personnel, and dedicated infrastructure.
Why Prioritisation Matters for Language Coverage
Speech data investment is finite.
When multiple organisations independently create similar datasets for the same language at the same time, those resources are often no longer available for:
- Lower-resource languages
- Minority dialect communities
- New domains or specialised use cases
- Regions with little or no speech data coverage
While some overlap is healthy in any market, unnecessary duplication can slow broader ecosystem growth by concentrating funding where data already exists rather than where it is still urgently needed.
Thoughtful prioritisation helps expand representation more effectively across the wider language landscape.
Community-Led and Research Contributions Matter
Research groups, universities, NGOs, and open communities such as Masakhane are foundational to speech technology progress, especially in early-stage research and open-access resource creation.
These contributors are particularly important because they often:
- expand coverage for underrepresented languages,
- create openly available datasets that accelerate experimentation,
- explore new methods before they are commercially viable, and
- strengthen local language communities through inclusive participation.
Their work helps ensure language technology development is not limited to the most commercially dominant markets.
Commercial Providers Help Scale What Works
Commercial collection providers bring a different, equally important layer of capability: building production-ready datasets with the operational, governance, and quality controls required for real-world deployment.
At Way With Words, this role typically includes:
- Operational Scale: Coordinating large contributor pools, multi-region recruitment, and complex collection logistics at volume.
- Production-Ready Quality Standards: Delivering consistency, validation, and documentation standards needed for enterprise use.
- Compliance and Governance: Applying structured consent management, privacy compliance, auditability, and licensing clarity.
- Long-Term Sustainability: Using revenue-generating delivery models to support continuous dataset expansion over time.
In practice, community-led and commercial models are complementary: one broadens inclusion and early innovation, while the other helps scale reliability, governance, and long-term delivery.
Why African Speech Data Presents Additional Challenges
Building African language speech datasets often involves additional complexity due to:
- Limited digitised text resources
- Significant dialect and accent diversity
- Orthographic variation between regions
- Infrastructure constraints during collection
- Smaller pools of experienced language specialists
These realities increase both the cost and planning required to build robust, representative datasets.
Sustainable Speech AI Requires Sustainable Economics
Speech AI development is not constrained only by technical capability, it is also constrained by economics.
To build responsibly at scale, organisations must fund:
- Fair contributor compensation
- Skilled transcription and annotation teams
- QA and validation processes
- Tooling and platform infrastructure
- Ethical and legal compliance
Without sustainable funding models, expansion into new languages becomes increasingly difficult.
Looking Ahead
As speech AI adoption grows, the challenge is not simply collecting more data, it is ensuring investment is directed where it can create the greatest long-term impact.
That means balancing demand, avoiding unnecessary duplication, and prioritising underserved languages and communities wherever possible.
At Way With Words, we believe the future of multilingual speech AI will depend on thoughtful collaboration across research, community, and commercial stakeholders alike.
If there is a language, accent, or domain you believe should be prioritised next, our dataset voting initiative helps guide future investment toward the areas of greatest demand and opportunity.